背景
はやいものであっという間に8月も終盤に差し掛かってしまいました。梅雨みたいな変な天気です
今月は16日から20日は休暇を取得して、9連休の夏休みを錬成しました。友人の勧めでこれまでやったことのなかった新しいオンラインゲームをやってみたり、ペーパードライバー講習がしたいとかいう後輩に自分の車の運転を任せたら開始1分経たずにガガガッと傷をつけられて大爆笑したりなどなかなか夏休み感のある夏休み感だったのですが
今回は自分への宿題として「最近流行りらしいBERT(バート)とやらでいくつか自然言語処理のタスクを試してみる」という目標を立てていました。
背景としては、
- もともと人間の言語というものや自然言語処理に興味がある(前にお世話になっていた長期インターンでも英文の採点システムの開発でごにょごにょしていた)
- この手法は学習データの面でも精度の面でも現実的に活用できそうで特に興味があった
- 本業の業務のこの先を考えてもこの辺の動向や何がどこまでできるか知っておくことは重要そう
というところです。
②についてもう少し補足すると、精度の面では、これまでのモデルの進化により文脈をより深く考慮した結果が出力できるようになったそうです。(最近のモデルでは単に直前直後を順々に考慮するではなくAttentionという仕組みで文章内のあっちこっちを参照できるようになっていて、そのAttentionを効果的に活用できているとか。厳密なことはまだ理解できていない。。)
また学習方法という面では、学習を「事前学習」と「ファインチューニング」の二段階に分けることで、大量の学習データを用意できる人が「英語のこういうタスク向け」とか「日本語のこういうタスク向け」とかの「事前学習済み」モデルを配布していて、そのモデルに対してこれからこなしてほしいタスクに特化した比較的少量の学習データをもちいて追加で学習することで(「ファインチューニング」)、比較的少量のデータから高い精度を実現できるようになっているそうです。
参考資料
この辺の話は↓のYouTube動画や記事がわかりやすかったです。YouTuberの動画で学ぶというのは初めてですがこれは無料でいいのかという感じでした
- 深層学習で進化する言語理解AI–「BERT」「GPT-3」は何がスゴいのか、何に使えるか?
https://japan.techrepublic.com/article/35174885.htm
写経に使った教材は以下の三つです。(三つめは要約の部分のみ)
- Natural Language Processing: NLP With Transformers in Python
https://www.udemy.com/course/nlp-with-transformers/ - 『BERTによる自然言語処理入門 Transformersを使った実践プログラミング』
https://books.rakuten.co.jp/rb/16733594/ - Natural Language Processing for Text Summarization
https://www.udemy.com/course/text-summarization-natural-language-processing-python/
やりたいこと
色々なタスクがこなせるそうなので、以下のそれぞれを実際に試してみることを目標としました。
- 分類(中でも「感情分析 」)
- 一般的なタスクとして「文章の分類」があり、その派生形として「ポジティブかネガティブか」を分類するタスクがあります
- 最終層の出力をどうごにょごにょするかにより「ポジティブかネガティブどっちか」の一択の分類タスクもできるし、「ポジティブ要素・中立要素・ネガティブ要素があるか」の複数選択の分類タスクもできるとのこと
- QA
- 質問を入力して回答を出力します
- 細かくは「文脈+質問」のパターンと「質問のみ入力して文脈は質問から予測する」のパターンに分かれるようですが、前者が基本的なパターンなようなので前者だけ
- 固有表現抽出(特に固有名詞)
- Udemyのコースにも本にもどっちにも載ってたのでやってみようと
- 最初はあまりピンとこなかったですが、音声アシスタントを実装しようと思ったら必須ですね。チャットボットなど作るときにも役立ちそう
- 要約
- そんなことできるの?!と思ったので
- これは「文中から抜き出しなさい」みたいなやつ(Extractive)と、「何文字以内でまとめなさい」みたいなやつ(Abstractive)に分かれるそうです
- 今回はライブラリになっているものを使ってみるとこまでしかできませんでした。実際に学習させる&日本語で、というところは今後の宿題ということにします
結果
何はともあれ物は試しということで動かしてみた結果を貼っていきます。
今回はクラウドGPUではなく手元のPCを使って回すことにしました。去年の年末にちょっとしたゲームができればと思い久々にPCを組んだのですが、そこで積んだグラボがこんなところで役に立ちました。(次はもっとVRAMが多いのを買う…)
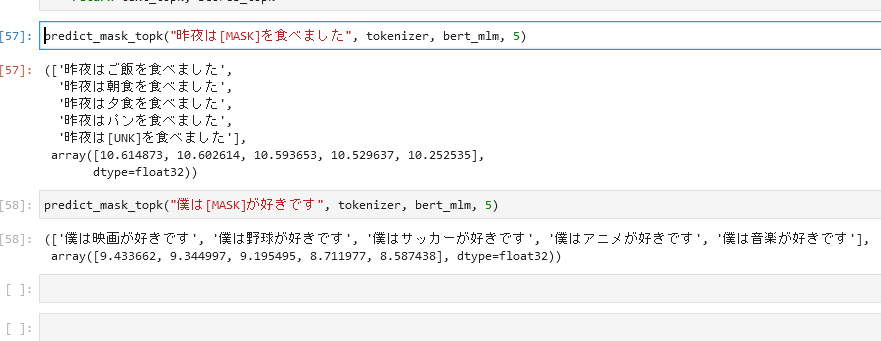
文の「虫食い」予測タスク
まずはチュートリアル的にこれが載っていたのでやってみました。
文の一部だけを隠して、そこに入るべき単語を予測します。「事前学習」はこのタスクで学習されているためダウンロードしたモデルそのままでそれっぽい単語を当てられます。
ちなみにBERTは文の生成を想定した設計・学習をしていないので大量の穴埋めになると変な結果が出てきてしまうらしい。
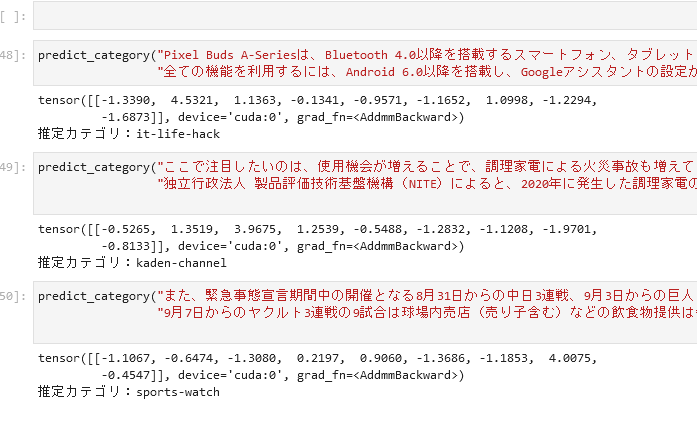
分類(一つだけ選択)への予測タスク
いくつか選択肢がある中から、「この文章はこれ」という分類を選択させます。今回はライブドアニュースの学習データで「記事のカテゴリ」を当てさせる例でした。実際に直近のYahoo!ニュースから適当な文を持ってきてもそれっぽい出力が得られました。
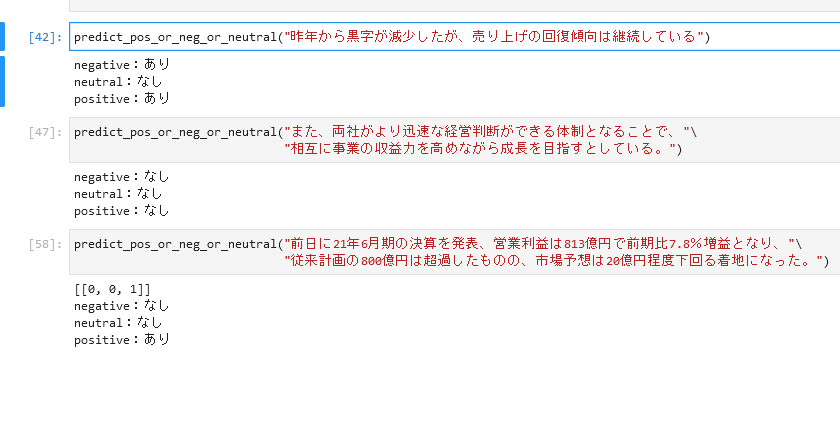
分類(複数選択)への予測タスク
いくつか選択肢がある中から、「この文章はこれとこれ」のように選択させます。今回の例は経済ニュースの文章に「ポジティブ・中立・ネガティブ」の要素がそれぞれ含まれているかどうかを推測します。
Yahoo!ファイナンスとか楽天証券とか見てるとこういうアナリストの分析載ってますね。(そういうのを機械的に数値化できると何千何万社の評価も簡単に出せるようになる的な?)
QA(Contextあり)タスク
「context」と「question(その文章についての質問」を与えて、回答を出力します。これはUdemyのコースの方にしかなかったので英語の例だけです。これ単体だと「Reader」というらしい。
色々質問を入れてそれっぽい回答が返ってくるとコンピュータと会話している気分になってきます。
例文の出典(別件で手元にあったので。。)
—
The Difference Between Copyrights, Trademarks and Patents
https://www.nytimes.com/article/copyrights-trademarks-patents.html
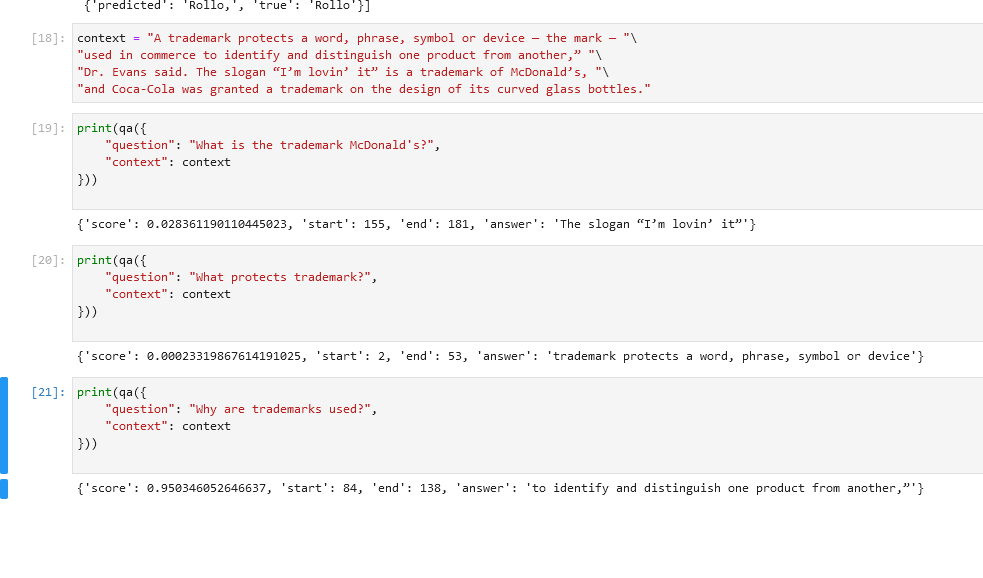
※質問の英文がちょっと変なのは気にしない
Udemyのコースではこのパターンに加えて、questionだけを入力して、questionからcontextを予測するタスクを先に実行したうえで、回答を出力するというパターンも紹介していました。(「Retriever – Reader」というらしい)
↑この一文を書いていて知ったけど「ゴールデンリトリバー」の「リトリバー(Retriever)」は「捕って戻ってくる」という意味なんですね
固有表現抽出タスク
固有名詞(やそれに準ずるもの)を抽出するタスクです。今回は固有名詞だけが含まれる学習データだったのれ例もそれに合わせています。一番目の例はカーナビを想定して考えてみました。

Extractiveな(抜き出すほうの)要約タスク
文章中から重要な部分だけを抜き出します。
これについては既に要約のタスクを学習済みのモデルが入ったライブラリを叩いてみるだけです。英語版ですが結構いい感じの結果が出ています
出典
—
Microsoft Windows
https://en.wikipedia.org/wiki/Microsoft_Windows
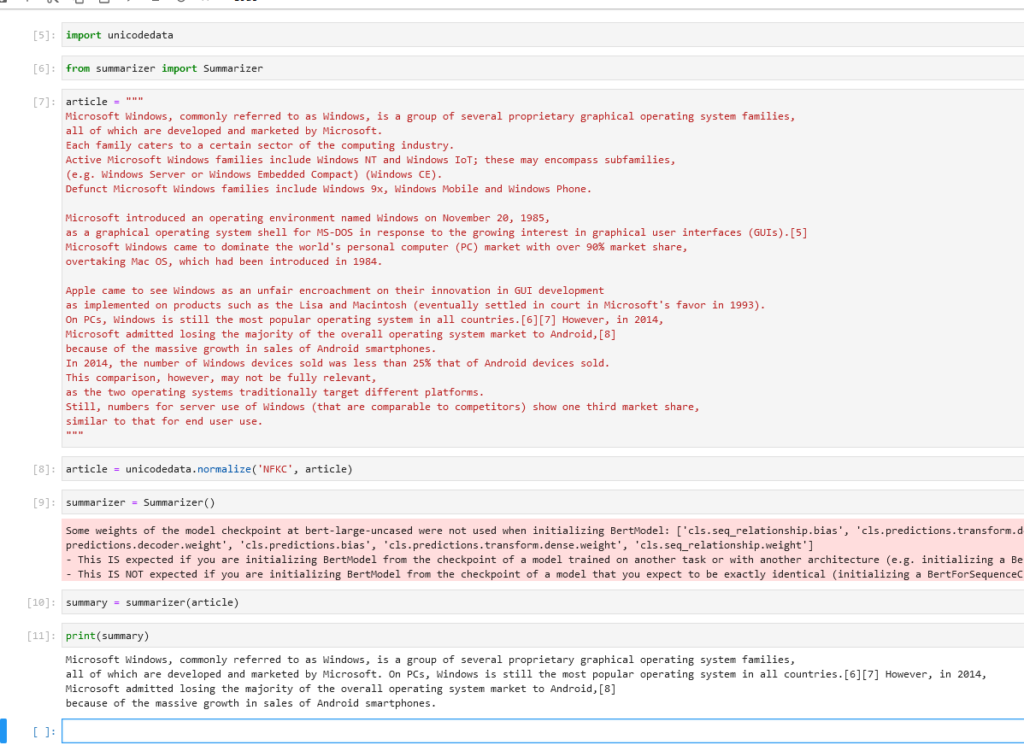
色々と調べてみたのですが、BERTでどうやって要約を実現するかについてはまだ発展途上なのかな?という印象です。あと他のタスクよりややこしそう。英語だとニュースサイトのデータセットがあるけど日本語はまだ整備途上というのもあるようです。
[DL Hacks]Pretraining-Based Natural Language Generation for Text Summarization ~BERTから考える要約のこれまでとこれから
https://www.slideshare.net/DeepLearningJP2016/dl-hackspretrainingbased-natural-language-generation-for-text-summarization-bert-141527380
番外編:誤入力(文中の単語一語)の修正タスク
本の方に面白そうな話が載っていたのでこれもついでに試してみました。誤変換を正しい変換結果に直すタスクです。Wikipediaの編集履歴をもとに生成された17万件の誤変換のデータから学習させています。(といっても自分で用意したデータではない)

感想
それぞれのタスクについて、コードはほぼ写経したものの、例の部分は自分で考えてみて、「確かにかなり的を射た出力が出るんだな」ということを体感することができました。
学習データがそんなにいらないといってもやっぱ数千件は用意しないといけないんだなというのはありつつも、確かにそれくらいなら頑張れば用意できるのかなという気もしてきます。
そもそも機械学習のコードを書いたことがなかったので、実際に手を動かしてみることができて良い機会になりました。今後は背景となっている実装や論文も少しずつ理解していくことと、ライブラリのインタフェースを理解していくことを目標とします。あとはせっかく機械学習をかじったのでレコメンデーションのほうも色々試してみたいですね。
Pythonのコードも本格的に書くのは初めてだったので良い勉強になりました。(グローバルな関数を多用しつつもオブジェクト指向な記法も活用していてPerlとRubyの間をとったような言語だなと)
また何か面白い学びがあったら書いていこうと思います。明日から仕事頑張ります