先月中頃、BigQueryにPreview版の機能としてPIVOT operatorが追加されたようです。
BigQueryでPreviewになったPIVOTとUNPIVOTを試す | DevelopersIO
https://dev.classmethod.jp/articles/bq-new-pivot/
Release notes | BigQuery | Google Cloud
https://cloud.google.com/bigquery/docs/release-notes#May_10_2021
ログデータなどをさっと集計したいときや、簡単なダッシュボードを作りたいときなど、行持ちと列持ちを変換したい場面は地味にありますが、これまではJOINしたりUNIONしたりなんとかしてゴニョゴニョしないといけないのが辛いところでした。
(そして大量のデータをJOINするのは結構時間がかかる)
特に行持ちのデータを列持ちに変換したい場面はままあるので、早速試験的に導入してみています。今回は備忘録&シェア用も兼ねて簡単にまとめていきます。
余計な列がない場合の集計
(あまり面白い例が思いつかなくて申し訳なさはありますが)こんなデータがあったとします。
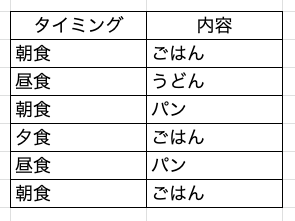
SQLのリテラルで書くとこんな感じです。
※以下ではここの WITH source AS (...) の部分は省略します
WITH
source AS (
SELECT
'朝食' AS time,
'ごはん' AS meal
UNION ALL
SELECT
'昼食' AS time,
'うどん' AS meal
UNION ALL
SELECT
'朝食' AS time,
'パン' AS meal
UNION ALL
SELECT
'夕食' AS time,
'ごはん' AS meal
UNION ALL
SELECT
'昼食' AS time,
'パン' AS meal
UNION ALL
SELECT
'朝食' AS time,
'ごはん' AS meal)
SELECT
*
FROM
source;

このデータを、タイミングごと・内容ごとの出現個数を集計したいとすると、Excelやスプレッドシートのピボットテーブルでは次のように実現できます。
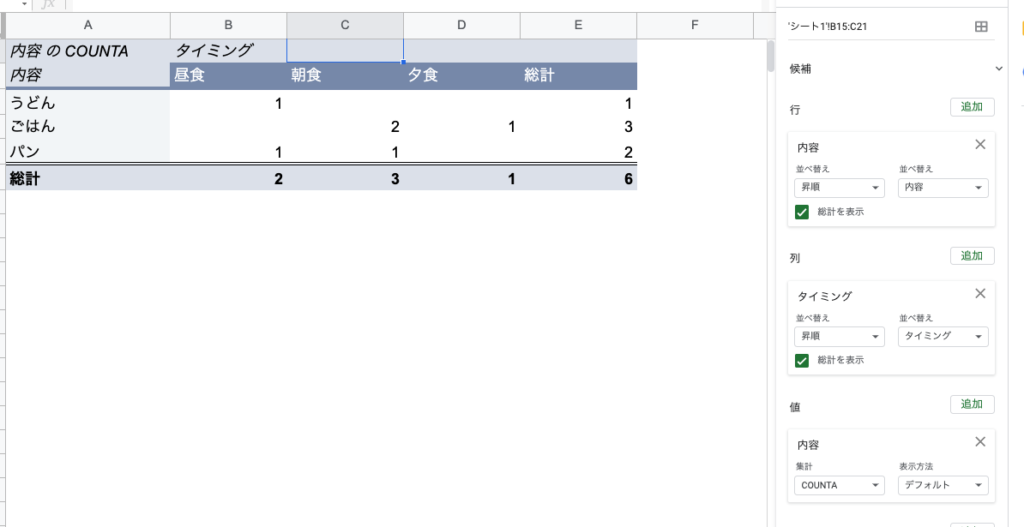
これが、今回導入されたPIVOT演算子ではこんなふうに書けます。
SELECT
*
FROM
source PIVOT (COUNT(1) FOR time IN ('朝食' AS breakfast,
'昼食' AS lunch,
'夕食' AS dinner) )
`PIVOT 集計関数 FOR 列 IN (列の値を列挙, …)` という文法です。
https://cloud.google.com/bigquery/docs/reference/standard-sql/query-syntax#pivot_operator
表計算ソフトのピボットテーブル機能では集計関数と列だけ指定すれば良いですが、BigQueryのPIVOT演算子では具体的にどんな値が来るか(「朝食」「昼食」「夕食」)を定数で指定してあげなければいけません。
また、BigQueryでは列名に日本語が使えないので、「朝食」「昼食」「夕食」をそれぞれ英数字で表現したエイリアスに置き換えないといけません。(これはPIVOTに限ったことではないですが)
という面倒くささはありつつも、一瞬でこんな結果が出力できます。
「行」にあたる部分は、「列」に指定しなかったカラムが勝手に割り当てられるようです。
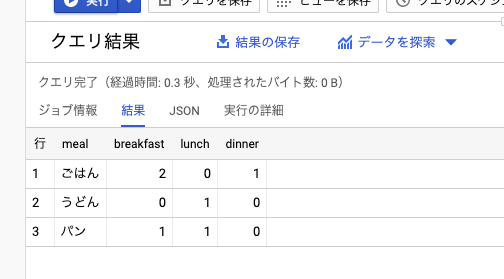
列の「朝食」「昼食」「夕食」はエイリアスに指定した「breakfast」「lunch」「dinner」に置き換わっています。
従来だったら朝食・朝食・夕食ごとに集計してJOINするなど何か手をつかってゴニョゴニョしないといけなかったところですが、簡単に解決できました。
余計な列がある場合の集計
先ほどの例のように「行」「列」に指定したい値しか入っていない場合はそれで良いのですが、その他にも集計に入れたくない列がある場合は、少し加工が必要になります。
例えば「年齢層」のような列があり、今回はこの列は集計に使いたくない、という場合です。
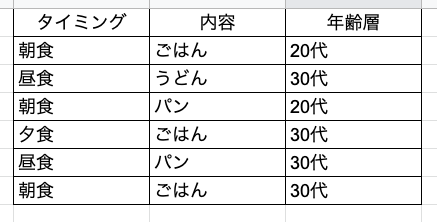
SQLではこんな感じ
WITH
source AS (
SELECT
'朝食' AS time,
'ごはん' AS meal,
'20代' AS age
UNION ALL
SELECT
'昼食' AS time,
'うどん' AS meal,
'30代' AS age
UNION ALL
SELECT
'朝食' AS time,
'パン' AS meal,
'20代' AS age
UNION ALL
SELECT
'夕食' AS time,
'ごはん' AS meal,
'30代' AS age
UNION ALL
SELECT
'昼食' AS time,
'パン' AS meal,
'30代' AS age
UNION ALL
SELECT
'朝食' AS time,
'ごはん' AS meal,
'30代' AS age )
SELECT
*
FROM
source;
前述の通り「行」の部分は余った値が勝手に割り振られるので、先ほどの方法で集計すると次のような結果になります。
SELECT
*
FROM
source PIVOT (COUNT(1) FOR time IN ('朝食' AS breakfast,
'昼食' AS lunch,
'夕食' AS dinner) )
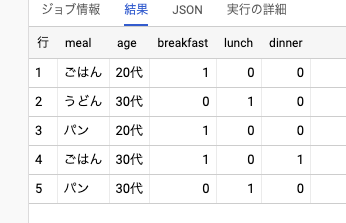
今回は「年齢層(age)」の部分は集計に入れたくないのに、入ってしまっています。
こういう集計をしたい場面もあるかとは思いますが、今回はいらないので、先に「タイミング」「内容」だけをSELECTしたサブクエリを使うことにします。
SELECT
*
FROM (
SELECT
time,
meal
FROM
source) PIVOT (COUNT(1) FOR time IN ('朝食' AS breakfast,
'昼食' AS lunch,
'夕食' AS dinner) )
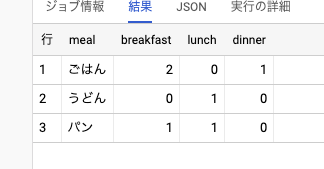
ということで、無事に使いたいカラムだけを使って集計することができました。
他にもSUMだとかAVGといった他の集計関数も使えるようなので、色々と使いようはあるのかなという感じです。
まだPreview段階というのは気になりますが、ぜひとも本採用になってほしい機能です。